Our Quick Manufacturing stencil calculates lead time for inventories based on Little's Law, which is totally reasonable and appropriate for discrete manufacturing. Rather than get into the nuances here, I guess I'll just link Karen's post on the topic because this post is supposed to be about what we did about our findings with the Transactional stencil.
So we looked at everything we did for mapping transactional value streams, and decided the biggest deficiency we had was in handling rework loops. We provided a very basic calculation for rework and left it at that, not even really having it impact lead time, just cost.
In the end we decided to try allowing loops in analyzing transactional value streams. We also had started implementing some calculations for parallel processing in the old Quick Transactional stencil, but wanted to provide full support for it going forward.
What came out of all this work is a new stencil, and a lot of supporting code, called Quick Transactional Pro. The stencil allows you to draw a transactional map with constructs available for multiple rework loops, document splitting and merging, and various termination points. We used constructs from Business Process Modeling Notation (BPMN), specifically: split, merge, and terminate centers.
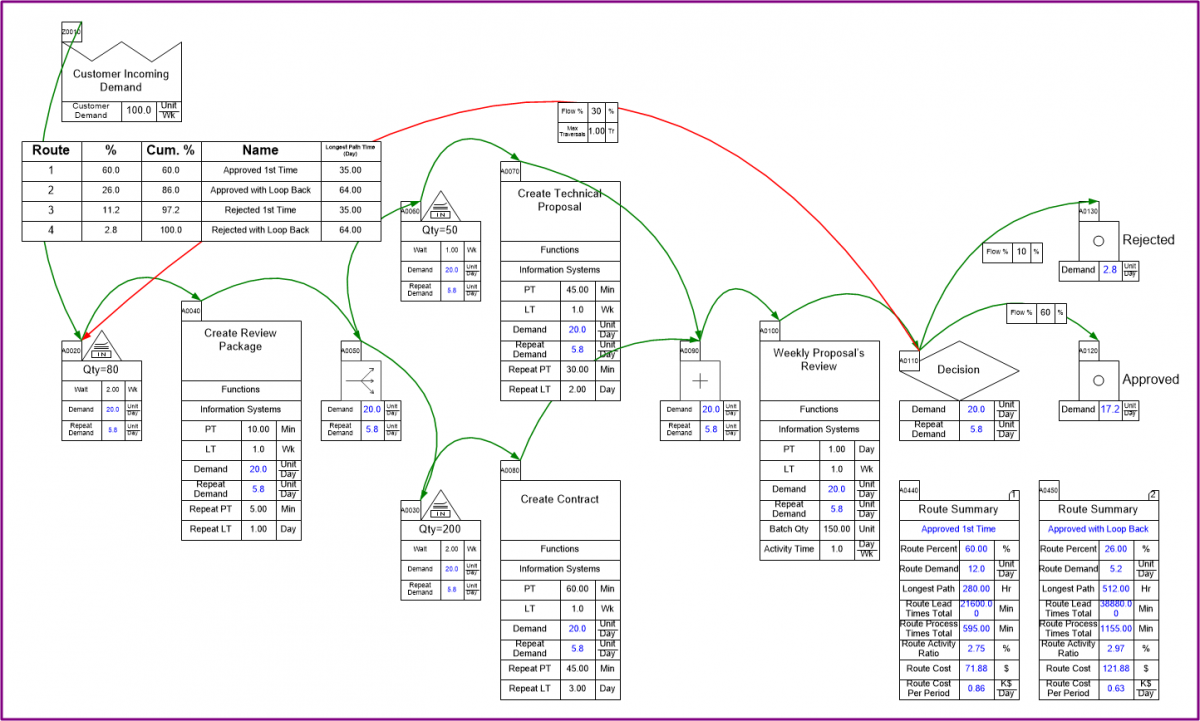
We tried to make the modeling job as easy as possible, so we end up assuming that the repeat process and lead times are the same as the first-time, but you can add repeat time data when the repeat processing is faster (or slower) than the first time through a process.
Once the map is built you use the Solve tool, which works a bit differently than normal on these types of maps. Rather than perform static Excel calculations, like all our other stencils, we run a three-stage solve. The first stage pre-populates some simple calculations, needed for the second phase. The second phase is a small scale simulation, where we generate some number of 'flow tokens' (250 by default), and send them one-by-one through the value stream. We track the whole route each token takes, and identify every unique route taken. We also count the number of tokens that follow each route.
This flow data is then passed to the third phase of the solve, which uses that flow data first to calculate the First-Time and Repeat demand at every single center in the value stream. This allows us to get a better idea of the actual demand faced by different resources in the value stream, and what capacity is required to serve demand.
The flow data also gets used in the third phase, to give route-specific lead times. We use the flow data to generate what we call a Route Table, which shows all the unique routes identified by the simulation, sorted from highest percentage of flow to the lowest.

The route table is a great way to tell at a glance what are the most common routes through the value stream, and their corresponding lead times. You can also drill down a little further into a single route with the Route Summary, which shows costs associated with a route, the demand, and the Activity Ratio, which is the ratio of Activity Time to Lead Time.
You can right-click on any row and view what activities are part of the route, and you can also see an animated view of the 'token' flowing through. If you want to know your first-pass C&A you would find the route where tokens flow through without rework, and get the flow %.
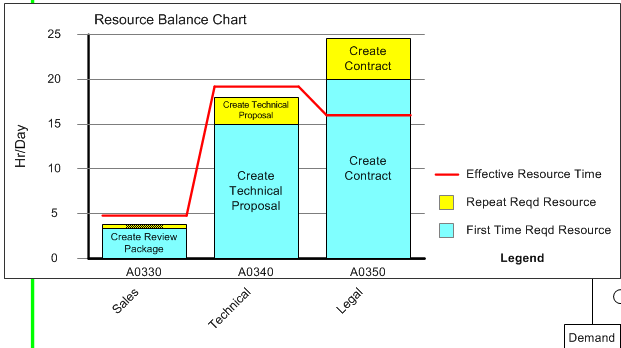
We also include a few charts, including a lead time ladder chart showing lead components for different routes:
This stencil has been out since last summer, but I've only now gotten around to talking about it. There are a few more exciting new tools in eVSM that I hope to write about sooner.
Quick Transactional Pro is a new way of thinking about mapping transactional value streams, and I can't think of an easier way to see transactional systems when there are loops and parallel processing.
Give eVSM v8 a try now, which includes Quick Transactional Pro. If it's been a while since you've tried eVSM, try it again.
No comments:
Post a Comment